LLMs need to interact with external services and data. The first-generation solution was to create rigid, imperative "tools", functions with fixed parameters. But that solution created its own problem; a fragmented ecosystem of incompatible tool definitions across Langchain, OpenAI function calling, Anthropic tools, and so on.
MCP addressed this fragmentation by providing a standard protocol. But the architecture involves multiple layers: the LLM calls a tool wrapper, which talks through the MCP protocol to an MCP server, which translates to an API call, which finally reaches the API. Information flows back through the same chain.
MCP solved interoperability, but are we standardizing the wrong layer?
APIs are already declarative interfaces. OpenAPI specs tell you what endpoints exist, what they accept, what they return, authentication requirements, rate limits, and schemas. The LLM should be able to read the OpenAPI spec, construct HTTP requests, and call the API directly.
Tool overload degrades LLM reasoning
Context windows are limited. Not just in their max windows of 128k or 1M tokens, but the window in which they're most effective. This is often around ~8-12k tokens, but it degrades at different rates per model beyond that. Attention then is a scarce, and precious resource.
Context rot and long context need-in-a-haystack studies show that as context length increases, the model's reasoning capability decreases, exceptionally so in the presence of distractors. When information similar to the needle is co-present, the quality of the output decreases even more than simple bloat. And that's essentially what we're doing by providing similar tool schemas all at once with every request. Some of my basic research on this effect in tools demonstrates how semantic crowding from similar tool definitions degrades both selection accuracy and reasoning quality.
But agents need to take actions in the world, from reading websites, to using github, notion, and other integrations etc. These capabilities have how-to's, schemas, that occupy space in the models context window. When you connect many of these tools to one agent, i.e. 'give an agent 3 MCPs', they can easily get overwhelmed because the toolset as a wall-of-text approach introduces distractors and pushes models past their window of highest effectiveness. These studies show that we're handling agent capabilities very poorly in relation to language models and the way transformer attention mechanisms work.
Agents ultimately need interfaces for interacting with APIs, and those interfaces today are custom/api-specific tools and MCPs. Many people in applied AI are building either custom functions or MCPs to wrap APIs in order to make them accessible to, and usable by, agents. MCP is the protocol that makes these custom tools compatible across clients, which is valuable progress.
However, MCP inherits the same constraint as standard function calling: exposing every tool and schema upfront with each call. As MCPs grow larger, giving multiple MCPs to one agent can overwhelm the model's coherence, leading to reliability issues. The model gets more confused the more tools you throw at it at once, which is a fundamental challenge with the current architecture rather than an implementation issue.
These issues are challenging to overcome through sheer brute-force model training, and while models will continue to improve, so can information architecture, and they work hand-in-hand in that improved models will actually think and work better with focused context and task.
Another problem with API-specific MCPs and function-based tools is that APIs are living things. They're subject to change. When an API changes, the MCP/Tools have to as well. This misalignment leaves MCP maintainers chasing after API updates, and can leave a lot of breakage if not maintained in lockstep.
Tools provide ergonomics, scope capabilities, and filter responses into focused outputs
Language models need to know what tools they have access to in order to take action. LMs also need to know how to use their tools, and tools self-document; they tell the LM what they do, and how to use them. Agents need clean, focused inputs, and sensible defaults to make them easy to use. There are a number of reasons we need tools, outlined in part in principles for building effective agent tools, which discusses the need for cognitive ergonomics, abstraction, and focused interfaces. Tools also allow developers to determine what actions are available to the agent; they're necessary to determine the capabilities the LM should and shouldn't have.
The outputs of tools should be filtered, focused, and structured in order to help the agent understand them, and focus its attention on the relevant information, without being overwhelmed with raw unformatted API response. API specifications are also massive, often ranging from 100k to 2-3M tokens, and that much context not only diminishes model intelligence but at todays prices the expense is prohibitive; we're talking roughly $5-$15 for basic tasks. Even with a 2-step compressor like janwilmake/slop, 30k-60k tokens-worth of endpoint lists with every call/loop is somewhat expensive. Tools also allow you to chain together API calls into one function for the agent to call.
Existing approaches work for small APIs but require embeddings, compression, or bloat context at scale
Why aren't we just using API's directly? Some do, more or less, and it's not really a brand new challenge or idea. But there are a number of reasons it's difficult, impractical, or impossible.
For one, some MCPs are actually just auto-generated from a service's OpenAPI spec. If the API is small enough, you can just wrap every endpoint in a function and call it a day. If you update your API it'll reflect in the MCP because it generates the MCP's functions at runtime from a spec. This only works for smaller APIs though, once you start approaching 40 or 50 endpoints, this approach ceases to work very well given current context window effectiveness and cost of context.
There's another approach, by janwilmake, that compresses API specifications into a list of endpoints and provides a get-details operation for LLMs to be able to read the endpoint details. It reduces for example Github's spec from roughly 2M to 30K tokens, showing first a persistent list of endpoints, and allows the model to get the details of an endpoint before calling. It's a step of progressive disclosure, but my tests showed that context rot still a factor when giving a list of endpoint names, especially as long as github's 700+ endpoint API. It doesn't handle requests, authentication, allowlists or response filtering though, as it's primarily focused on API navigation and discovery.
RAG search over APIs exists, but there's upfront setup of chunking, generating embeddings, and searching against a vector db. And many of these search/explore tools don't handle authentication or execution.
Eight universal tools let agents explore and call any API without the context window changing size
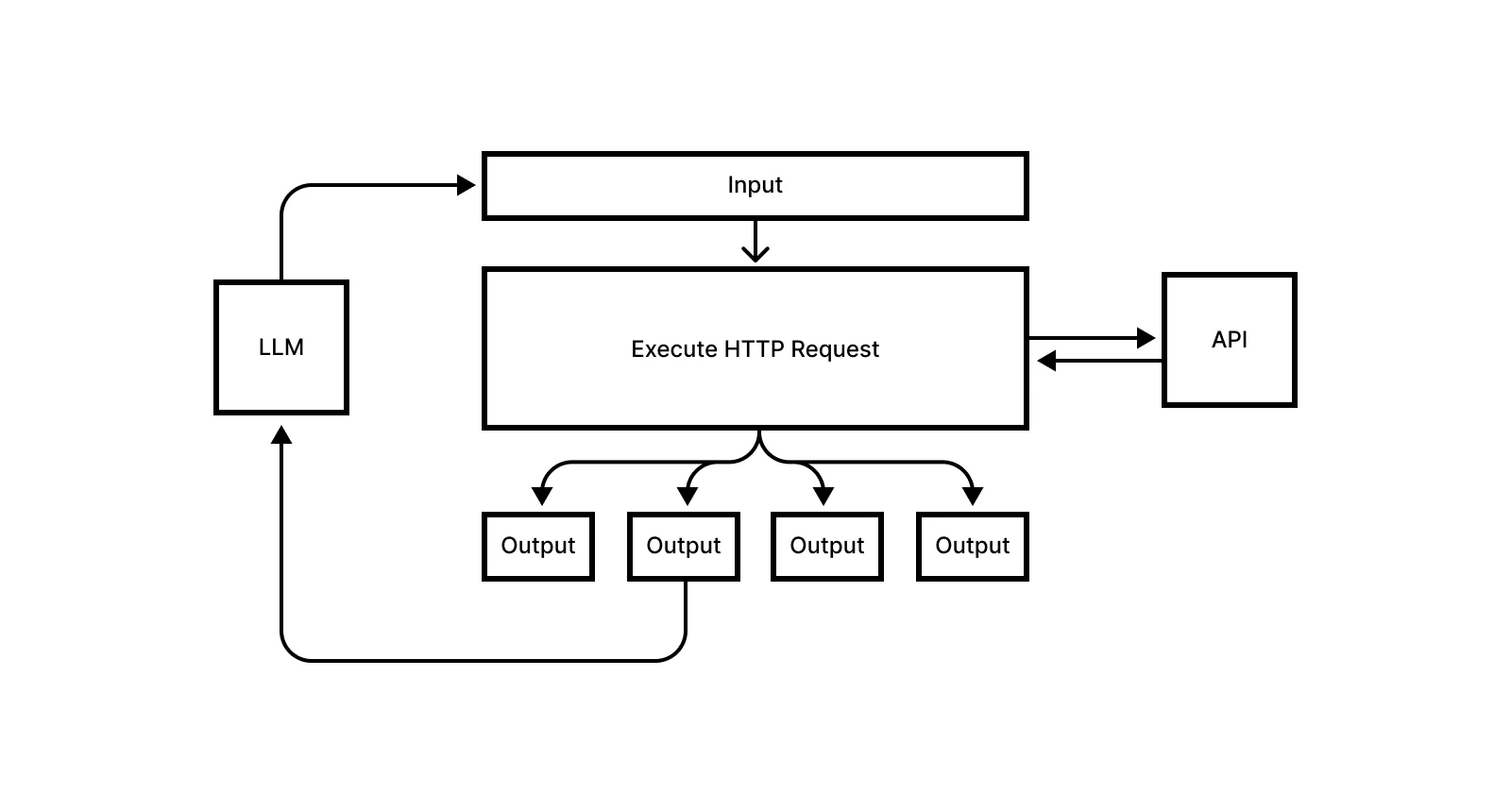
This approach involves eight universal tools that enable any agent to explore and interact with any API with an OpenAPI spec URL. Just pass the spec URL to the system prompt or in a message, and the agent can load it up itself, navigate it, and interact with it via HTTP requests that handle authentication. The LLM explores the API incrementally, almost like a filesystem, examining categories, searching, reading details, and executing requests.
The toolset itself is only around 1-2k tokens, and it enables agents to navigate and view the entire OpenAPI spec of a service like GitHub with 737 endpoints. The context window stays the same regardless of how large the specification is, because it's not doing any distillation or ingestion at the base level, it only has the eight tools, rather than a compressed spec.
This is a unified approach to make all APIs compatible with agents. APIs are already self-documenting via OpenAPI specifications. Rather than building protocol layers for interoperability, we can improve the architecture of tool-use to work directly with the standards that already exist.
And yes, this is packaged as an MCP server. The irony isn't lost. But if we're going to use MCP, we might as well use it to make API-specific MCPs unnecessary.
Philosophy: Give agents more agency to discover and construct their own capabilities
The traditional approach to tools involves dumping pre-built function schemas into the context window with every call to the language model. Instead, with this approach we give it the tools to navigate, discover, and call endpoints based on a loaded specification. It means the tools don't change depending on the API, and it can technically be passed multiple specifications covering hundreds of tools with the same universal toolkit.
The Universal Tools
The toolkit provides eight functions: load_openapi_spec for dynamic spec loading, search_operations for fuzzy search with scoring, get_categories for hierarchical navigation, get_resources_in_category for further exploration, get_operation_details for just-in-time endpoint information, get_service_info for service metadata, execute_http_request for actual API execution that handles authentication, and execute_chained_http_request for threading together multi-step API calls.
Each function has a clear purpose, and the agent can hold the entire toolkit in working memory, and the total schema occupies under 2,000 tokens regardless of how many APIs are loaded or how large their specifications are.
Loading specs into searchable memory so the full specification never enters context
The load_openapi_spec handler accepts either a URL pointing to an OpenAPI specification or raw JSON/YAML content. The parsed specification is stored in memory with its service name, base URL, and path count, and the actual spec never enters the LLM's context. The agent gets a summary under 200 tokens confirming the service is available: "GitHub API loaded, 737 endpoints ready."
You can load multiple specs without overloading context; meaning you can give the agent 5 specs and it'd be able to use all 5 APIs with one MCP.
Keyword search scoring surfaces relevant endpoints without vector databases
The search_operations handler implements a deterministic keyword scoring system without vector databases or embeddings. It splits the query into words and scores matches across path, method, summary, description, and tags fields. Exact phrase matches in summary or path rank highest, followed by query words in path segments, tags, method matches, and partial substring matches. Results are sorted by score and capped at 25 operations, typically 500 to 800 tokens total. This is how "get repository by owner" across GitHub's 737 endpoints returns a handful of relevant operations.
This is simple, fast, and works well as a fuzzy keyword search with typo tolerance. No preprocessing required, no embeddings to generate and store, no vector database to query or maintain. Just a cheap scoring function that runs in milliseconds and returns focused results without the infrastructure overhead of semantic search. It keeps the entire system lightweight and portable so you can spin it up anywhere without dependencies on external vector databases or embedding models.
Retrieving just-in-time endpoint details replaces dumping hundreds of schemas upfront
The get_operation_details handler takes a service name, HTTP method, and path, then returns the schema for that single operation. Output includes summary, description, parameters with locations and descriptions, whether request body is required, response schemas showing what the endpoint returns, and response codes, which typically amounts to ~100-300 tokens.
This is the key moment where the LLM gets operation details and is usually followed by a call to that endpoint, unless the details reveal it's unsuitable for the task at hand. It shows both what the endpoint expects as input and what it will return as output. This replaces the function schema in behavior, but only puts one endpoint in context at a time instead of hundreds. The LLM examines the exact requirements and expected responses, decides if it's the right tool for the job, and either proceeds with a request or searches for something else.
Filtering dangerous operations from the spec before the LLM ever sees them (and rejecting them if they somehow emerge)
Access control filters the specification before the LLM ever sees it. The system reads OPENAPI_ACCESS_RULES from environment variables as JSON mapping service names to allowlist or denylist patterns. Patterns like "GET /repos/" or "POST " match against method-path combinations.
When a spec is loaded, the handler walks through every operation and filters out anything that doesn't match the rules. The filtered spec is what gets cached and used for all subsequent operations like search, navigation, details, execution. If you deny all DELETE and POST operations for GitHub, those endpoints simply don't exist as far as the LLM is concerned. It can't see them in search results, can't navigate to them, can't call them. GitHub filtered from 737 to 586 visible endpoints means 151 operations that never appear in any interaction, compounding token savings across the entire conversation.
If a model were to know an API well enough based on training data, or find information on a disallowed endpoint via web or other sources, the execute_http_request tool is designed to block any calls that violate the access rules set in the environment variables. Instead of executing the request, the tool returns early with a message "Operation denied: POST /repos/philippe-page/universal-openapi-mcp/issues is not permitted due to access control rules. This endpoint is blocked by server configuration. Do not attempt to call this endpoint again.".
Executing authenticated requests with credential handling and path resolution
The execute_http_request handler resolves URLs from path templates by substituting parameters, combines relative paths with base URLs, fetches auth configuration, builds headers and query parameters, and executes with a 30-second timeout. Responses that are JSON get parsed. Base64-encoded content gets decoded and stored with both versions.
Response filters allow agents to specify which fields to project, cutting response data by 75-98%
Response filtering prevents context explosion across multi-turn tasks or when interacting with an API that returns a lot of data in its response (like Github often can). execute_http_request's response_filter accepts JSONPath strings or structured objects that allows the agent to actually view (or ignore) those specified fields in the response. The LLM knows what it's looking for; why bother pre-specifying these filters?
The structured form composes operations: navigate with jsonpath, project with fields, paginate with limit/offset. Field projection works on objects and arrays, projecting "id,name" on an array of objects returns that array with only those two fields per object. Filters apply after the HTTP response but before returning to the LLM.
Any filter path returning undefined fails the request with an error telling the LLM that path doesn't exist. In early testing with response_filters enabled the reduction of response data ranges from 75% to up to 98% when retrieving a small detail from a large response. This keeps context window lean, avoids context rot, and keeps unnecessary costs down.
Noise refers to unwanted data that interferes with meaningful information. When a GitHub API response returns 14k tokens of repository metadata but the agent only needs the name and star count, that extra 13.5K tokens isn't just waste, it's noise that occupies attention heads and dilutes the model's focus on relevant information. Studies on long-context performance show that context bloat degrades reasoning quality.
Response filters address this issue that emerges from interacting directly with APIs without custom functions. Rather than bringing raw API responses into context and hoping the model extracts what it needs, agents declare upfront which fields matter. The filter executes before the response enters the LLM's context window. The agent essentially self-curates its incoming information stream, keeping signal-to-noise ratio high across multiple tool-use loops. A search returning a noisy 20,000 tokens gets projected down to 400 tokens of signal. The transformer never sees the noise, so it doesn't have to waste attention on it.
Reading security schemes from the spec and injecting credentials
The auth system reads security schemes from the OpenAPI spec, checks environment variables for credentials using standard patterns, and handles bearer, basic, apiKey, and OAuth2 flows. The LLM never sees credentials, never constructs auth headers, never needs to know which auth type an API uses. Most importantly, credentials aren't exposed to the LLM.
Request Chaining: Threading outputs between steps so multi-call workflows become single tool invocations
One of the purposes of tools is to let a single callable execute multiple API calls in sequence. The execute_chained_http_request handler allows the LLM to make one tool call that chains API requests together, routing outputs from earlier steps into the inputs of later steps.

Each step in the chain gets a step id, and its response is stored for later reference. Subsequent steps can reference earlier results using variable substitution: search for repos and get an array, then use the first repo's name in the next call, then use the second repo's name in another. Or get repo metadata, extract the default branch, and use that branch name to fetch commits.
This turns multi-step workflows from separate tool calls spread across multiple turns into a single chained call. The LLM describes the workflow once, the chain executes it, and only the final result enters context. Three API calls that would normally cost three turns of back-and-forth, and the agent manually passing outputs into the subsequent calls, becomes one.
The purpose or point isn't that it reduces back and forth, it's that it enables usecases that would otherwise be prohibitive with individual calls.
Consider a traditional tool like summarize_web_search. It takes a query input from an LLM, searches for articles, scrapes each URL, then uses an internal micro-agent to summarize each result. The summaries get passed back to the caller. This multistep, multi-endpoint operation with its paths hardcoded will reliably execute that flow. The predefined organization serves one key purpose: routing information through endpoints without the caller having to handle intermediate data.
With just a single execute_http_request tool, the caller would have to fetch the URLs, then manually construct subsequent scrape requests for each one. That's manageable; five URL strings isn't too much to route. But the third step, summarization, reveals the problem. The calling agent would need to hold all five article outputs in memory and manually regenerate that content in each summarization request to the sub-agent. It would have to write "summarize this article: [full article content]" five separate times. Wasteful in tokens, time, and cognitive effort, not to mention error-prone in transcription. One of the remaining reasons to use hardcoded tools is precisely this: data passing and control flow that agents can't manage themselves.
Or can they? With chained http requests, the agent could actually hit three endpoints in one call and control data flows so it doesn't have to rewrite article content into the final summarization requests. It routes data determined at runtime, letting the output of one call feed into the next as an input without the agent rewriting anything. This is done through JSONPath strings and variable replacements between steps in the chain.
Spawning Agents as Emergent Tool Behavior
This enables, perhaps as an interesting side effect, the placement of LLM requests in the chain. If you give the caller agent the API spec of an LLM provider, it can spawn ephemeral agents to do work without any custom tools or agentic framework. The agent selects the provider, model, system prompt, temperature, and instructions at runtime. From the parent agent's perspective, it called one tool. Internally, that tool spawned five parallel LLMs and their contexts to process results.
We've Been Building the Wrong Abstractions
The agent tooling stack evolved to solve real problems, but each solution created new ones. We built rigid tool schemas when APIs already document themselves. We built orchestration frameworks when protocol primitives can be composed on-the-fly. We built interoperability layers to bridge incompatible tool definitions when the underlying APIs already speak a common language through OpenAPI.
MCP solved interoperability between custom tools, which was important. But there's a more fundamental question: what if we didn't need API-specific tools in the first place? Give agents eight universal functions and the ability to read specifications, and they can interact with any API without custom code!
Discovering and building capabilities dynamically instead of hardcoding them
Every API-specific tool or MCP is technically hardcoded. We don't usually think of tools that way, but that's what they are. Someone sat down and wrote fixed schemas mapping API endpoints to function definitions, and now agents are constrained to those exact capabilities until someone updates the code. When the API changes, the tool breaks. When you need a different combination of calls, you write a new tool. We've been treating agent capabilities as if they were static and pre-determined instead of dynamic, discoverable interfaces.
This approach gives agents... agency. They discover, navigate, determine which endpoints solve their task, construct requests with parameters and filters on-the-fly, chain operations together, and spin up ephemeral sub-agents with custom prompts and models to summarize or transform data. If an agent can write code, it can figure out an endpoint call with JSONPath filters and chained requests. If it can reason about complex problems, it can determine what temperature, model, and instructions a sub-agent needs to process a specific piece of work.
The agent isn't limited to the tools someone decided to build, it has the primitives to construct whatever capability is required. It learns which patterns work, surfaces them as specialized tools, and adapts as usage evolves.
Repo: github.com/philippe-page/universal-openapi-mcp
The same approach is also available as a toolkit of functions exported for Anthropic SDK, OpenAI SDK, and AI-SDK: github.com/philippe-page/openapi-toolkit.