After reading Chroma's paper Context Rot, I began to see a connection between their findings on distractors and the challenges facing agent tool selection. Their research demonstrated that giving many semantically similar but incorrect options degrade language model performance. Massive tool catalogs with many similar functions might be creating the same distractor effect for agents; tools and their schemas could actually be functioning as distractors that reduce a model's performance.
So I decided to test this theory out by building an agent with 128 different tools covering everything from messaging and file operations to database queries. I gave eight different state of the art models the same set of tasks and measured how well they could pick the right tool and use it.
First, I tested the standard approach: dump all 128 tool schemas into the context at once and let the model choose. Most models in this environment struggled, achieving only 80-90% accuracy in selecting the correct tool for each task, with quality scores ranging from 70-90%.
Then I tried a hierarchical approach: organize tools into categories, let models browse categories first, then drill down to specific tools and their instructions. The results were promising, seven out of eight models jumped to 100% tool selection accuracy, and six out of eight showed an improved quality score in how they used their tools.
Emerging Research
The Context Rot study by Chroma provides an analysis of eighteen leading models, including GPT-4.1, Claude 4, Gemini 2.5, and Qwen3, revealing insights that validate the hierarchical tool discovery findings presented here.
Their "repeated word test" where models simply had to copy sequences like "apple apple apple apples apple" showed systematic failures as context length increased. Claude models proved most resilient but still degraded beyond 8,000 tokens, while GPT models exhibited erratic behavior with random refusals and hallucinations.
From Chroma's Context Rot:
 The study's distractor experiments are quite interesting: when semantically similar but incorrect information was present alongside correct answers, models increasingly selected wrong options as context grew longer. Chroma's research showed that even a single distractor can hurt performance, while multiple distractors cause performance to drop off dramatically.
The study's distractor experiments are quite interesting: when semantically similar but incorrect information was present alongside correct answers, models increasingly selected wrong options as context grew longer. Chroma's research showed that even a single distractor can hurt performance, while multiple distractors cause performance to drop off dramatically.
Also from Context Rot:
 Perhaps most importantly, their research confirms that the problem isn't simply about finding information in long contexts, but about the cognitive load of processing semantically crowded environments.
Perhaps most importantly, their research confirms that the problem isn't simply about finding information in long contexts, but about the cognitive load of processing semantically crowded environments.
The Problem
Tool-use is essentially a needle-in-the-haystack test. Given a system prompt, conversation history, and tool list, the agent has to pick a tool and reason over inputs based on what's relevant in the context window. These long tool lists and schemas begin to cause context rot as they grow. If these tools are similar to each other, they become distractors to all other similar tools. These distractors then affect the attention mechanisms and degrade reasoning. The LLM basically gets distracted and focuses on the wrong tools. Not only does this mean models select the incorrect tool more often, but it means that the reasoning is already degraded at the time it specifies the parameters, reducing its output quality and complexity, leading to more hallucinatory responses or buggier code generation, for example.
The space
This problem has begun attracting attention from the research community. Recent work on MCP-Zero identifies the same core issue: "Current LLM agents inject thousands of tool schemas into prompts, creating massive context overhead and reducing models to passive tool selectors rather than autonomous agents." Their framework introduces active tool discovery through hierarchical semantic routing: a two-stage algorithm that first filters candidate servers, then ranks tools within selected servers.
Similarly, RAG-MCP addresses what they term "prompt bloat" in tool selection, reporting over 50% reduction in prompt tokens and tripling tool selection accuracy through retrieval-augmented approaches.
What's interesting is how consistently these independent research efforts identify the same fundamental tension between a language model's reasoning capabilities and the information architecture we provide it. While previous work has focused primarily on RAG, this research examines the cognitive and architectural principles underlying tool organization; investigating not just how to find tools, but how to structure tool presentation to work with, rather than against, transformer attention mechanisms.
Simple Solutions
What's encouraging is that we don't need complex RAG systems or rerankers to see improvements. This approach uses just three basic components: a category list, a tool to view the list of tools in a category, and a tool to view a tool's schema. Just by providing progressive information architecture, it achieved performance gains seen in other complex systems.
This suggests that the real opportunity lies in recognizing that even basic improvements to how we organize information can unlock latent capabilities that were already there, and that models are just being hindered by ineffective presentation.
The Cost of Cognitive Overload
The problem stems from a fundamental mismatch between how we typically give agents tools and how transformer attention actually works. Most production agents follow a pattern that seems logical, show the model every available tool with complete documentation, then let it choose what it needs. In practice, this creates confusion when many similar options compete for the model's attention simultaneously.
This appears to stem from how transformer models process large sets of semantically similar options. Just like Chroma's research shows with "needles", when many tools share similar semantic features model performance degrades. The phenomenon involves similar stimuli interference during processing, making discrimination more difficult even when the correct choice has distinguishing features.
Consider a real example. When asked to perform email operations, models faced choices between gmail_send_email, gmail_create_draft, gmail_save_draft, gmail_trash_message, and dozens of other similar functions all presented together. When multiple tools are extremely similar to each other, the model's output probability distribution becomes more diffused across the similar options, and confidence in selecting the correct token decreases.
Insights
Initially, I tested a simple two-step progressive disclosure pattern where I showed only a list of tool names and descriptions upfront, and had the agent fetch specific tool schemas when needed.
To test this two-step process, I used GPT-5 as an LLM-as-a-judge evaluator to assess tool call parameters for depth, accuracy, and overall quality. This was useful for qualitative assessment and it demonstrates the model's reasoning quality at the time of tool calling. Tool selection accuracy was measured deterministically, since the required tool was known it was possible to track whether models selected the correct function.
The majority of models tested showed quality improvement from the two-step process. But, interestingly enough, tool selection accuracy actually decreased relative to the all-at-once ‘monolithic’ exposure. Even though they were using their selected tools well, they were selecting the wrong tool more often.
The problem was that displaying 128 tool names simultaneously creates a decision space just like the monolith of schemas; enough length to overwhelm, and enough self-similarity to degrade selection accuracy. Semantic interference doesn't disappear simply by removing full schemas, it seems that it persists whenever too many similar options compete for attention, even if it represented fewer tokens.
This led to an insight about the nature of semantic interference in large tool catalogs: I needed to introduce an intermediate categorization layer that groups tools into clusters before exposing individual tool names. This removes similar tools from context and prevents them from distracting attention from each other. For example, Notion's database operations are very similar to Google Sheets operations, and Slack messaging functions resemble Gmail operations. Keeping these out of the same context window would, in theory, reduce the distractor effect.
The ideal approach emerged as a three-stage hierarchical discovery process. Models first encounter a small list of high-level categories like gmail_tools, notion_tools, or slack_tools. After selecting a category, they see a list of the tool names within that group, facing perhaps twenty tools at a time instead of all 128. Only when the agent has chosen a specific tool does it receive the full schema for parameter specification, removing even the other tool names from context window at time of parameter creation.
This change resolved the tool selection accuracy issue and actually outperforms the monolithic all-at-once tool schema approach in terms of accuracy in selecting the correct tool for the job when overloaded with 100+ tools.
This is about progressively revealing complexity through the right structure at the right time. Each level of the hierarchy serves as a filter, reducing the search space by an order of magnitude while removing similar but irrelevant tools from context.
Tool Selection Accuracy
The improvements are pretty noticeable. Given 128 tools, many of them sharing similar purposes in different apps (gmail and slack, notion database and google sheets), the majority of models tested showed improvement in their tool selection accuracy.
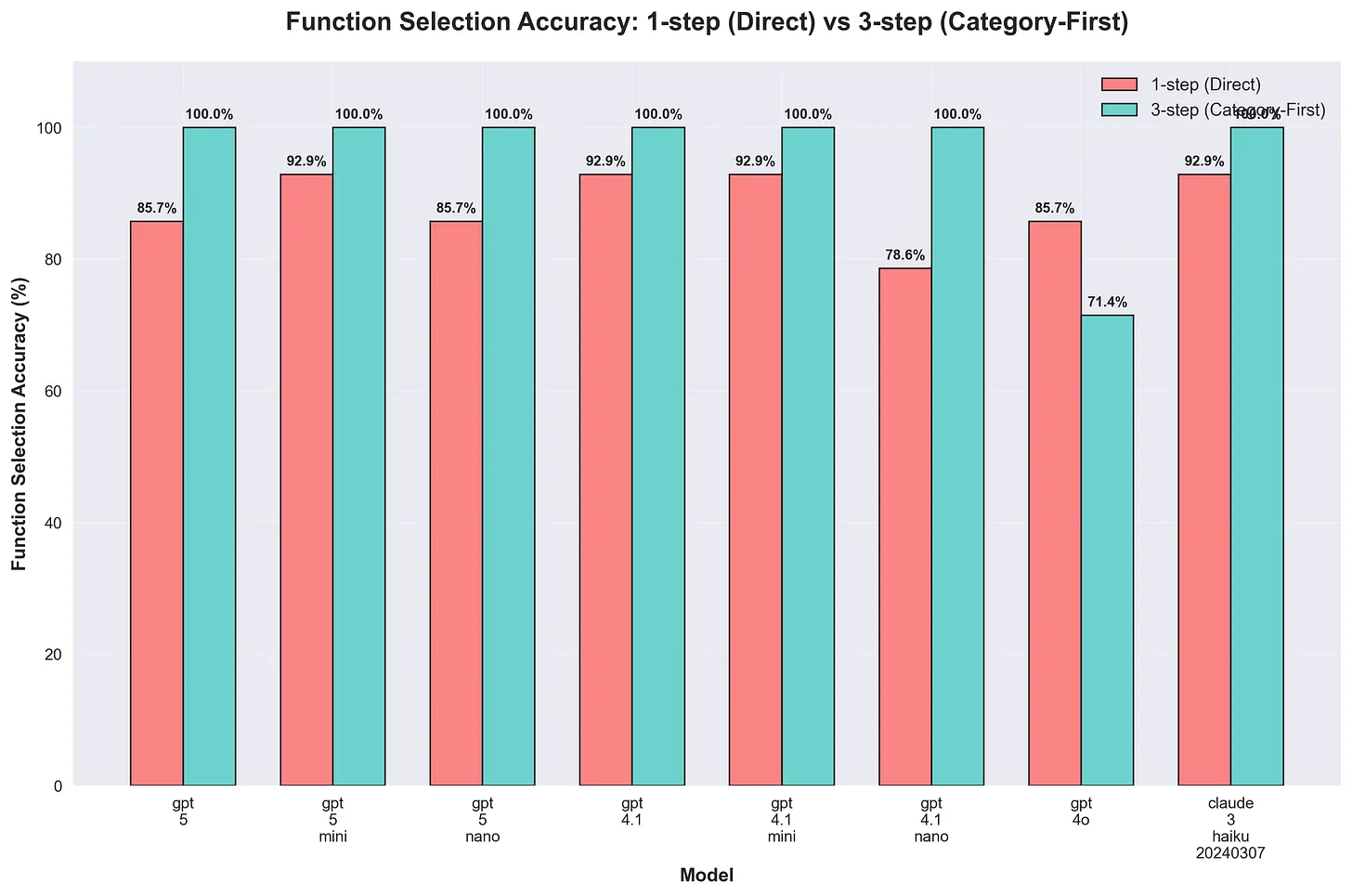
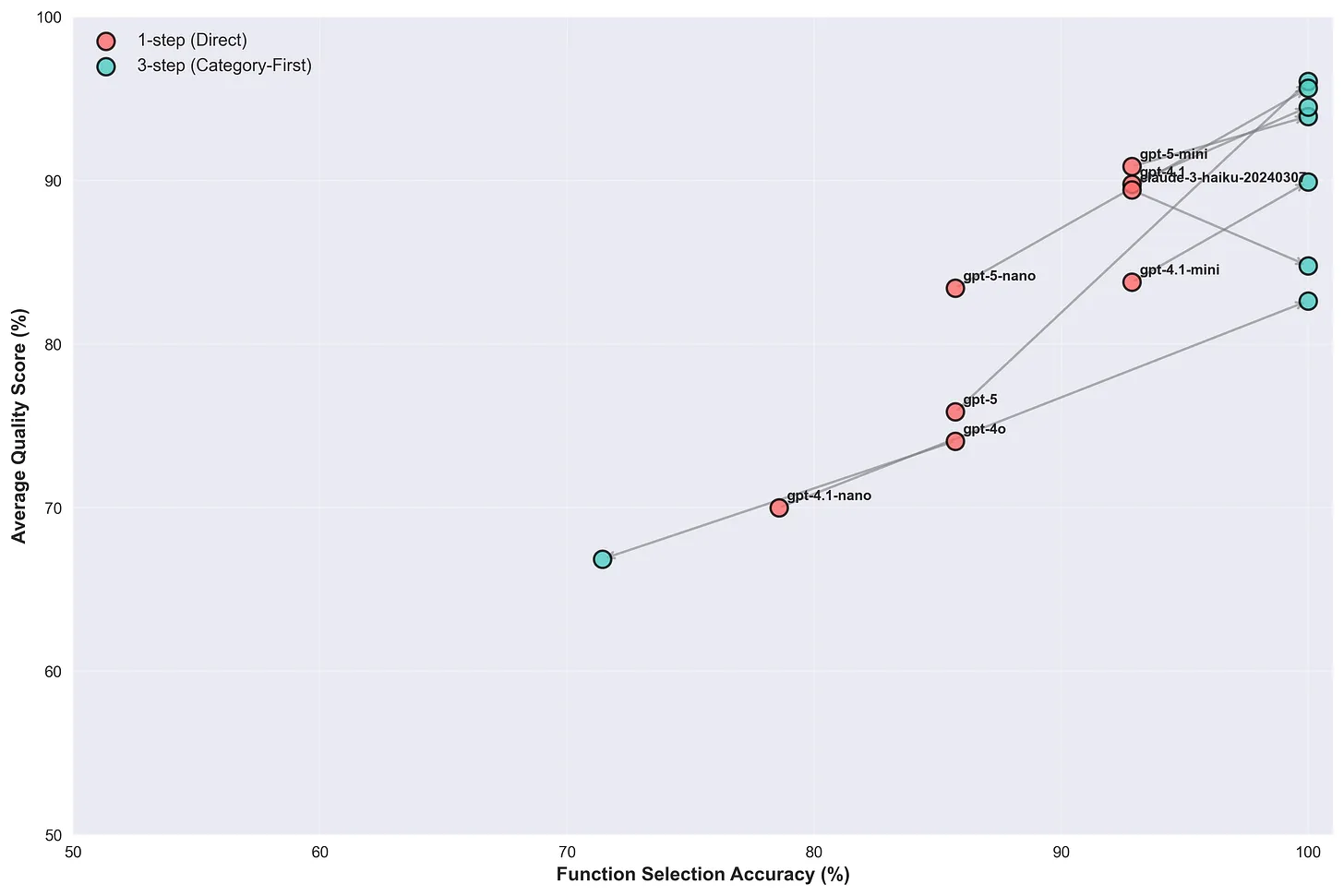
GPT-5 jumped from 85.7% to 100% tool selection accuracy with quality scores improving from 75.9% to 96.1%. GPT-4.1 moved from 92.9% to 100% accuracy with quality improving from 89.8% to 94.5%. GPT-5 nano achieved perfect accuracy with the three-step approach (up from 85.7%) while improving quality scores from 83.4% to 95.6%. GPT-4.1-nano also reached perfect accuracy, up from 78%, with quality improving from 70.0% to 82.6%. Claude 3 Haiku maintained strong performance, moving from 92.9% to 100% accuracy, though quality scores actually decreased from 89.4% to 84.8%. Interestingly enough, GPT-4o actually degraded in both accuracy and quality, selecting the correct tool only ~71% of the time (down from ~85%) with quality scores dropping from 74.1% to 66.9%.
Tool Quality Comparisons

Even when models successfully selected the correct tool under monolithic exposure, they often provided incomplete or malformed parameters. The hierarchical approach consistently produced higher quality parameters when scored by an LLM-as-a-judge, suggesting that the cognitive burden of processing tens of thousands of tokens of semantically similar distractors interferes with the model's ability to reason effectively about parameter specification.
Under hierarchical discovery, the same models produced more sophisticated parameter configurations like more detailed email content, complex database queries with proper filtering, and richer formatting specifications.
Why Some Models Handle Chaos Better Than Others
One of the most interesting insights was that, like in the Chroma Context Rot research, different model architectures showed different resilience against tool crowding. Anthropic's Claude models maintained high performance even under monolithic exposure with Claude 3 Haiku achieving 89.4% quality score with all 128 schemas present simultaneously, actually showing a decrease in quality to 84.8% under hierarchical organization. GPT-4o dropped not only in accuracy but also quality, with parameter score degrading from 74% to 66% with the progressive system.
This speaks to the fact that there are fundamental differences in attention mechanism implementation and training methodologies between model architectures. While Claude models show consistent baseline performance under monolithic exposure, GPT-5 gained 26.6% in quality scores through three-step hierarchical organization. Model improvement varies even between similar architectures (GPT mini series vs nano series), suggesting that not all architectural improvements apply uniformly across models.
Organizations using different model families would need tailored approaches. GPT-5 users would see benefits from hierarchical organization, while Claude users maintain more consistent performance regardless of approach.
The Broader Context of Attention and Choice
The implications extend beyond tool use to any scenario where language models must choose among many similar options. The same principles apply to RAG systems with semantically similar documents, multi-agent scenarios with similar roles, or any interface where models face similar or overlapping choice sets.
This research validates several design principles that contrast with current common practices. Rather than optimizing for completeness by showing every available option in full detail, systems could be optimized for discriminability by showing fewer, more distinct options at each decision point.
Attention budget should be treated as a precious resource. It should be allocated strategically rather than saturated with information. It could be said that to avoid context rot, practice good context hygiene. Tool naming and description conventions should maximize discriminability, and context should be pruned or cleaned when possible.
Token Efficiency
Logging token usage in testing showed that the layered discovery method uses ~80% fewer tokens per task compared to the monolithic approach, dropping from an average of ~27,000 tokens to just ~5,300 tokens while simultaneously achieving better accuracy and quality. This measurement represents just a single tool call, but agent workflows routinely require 2, 5, or even 10+ sequential tool interactions, increasing savings over time.
The efficiency improvements stem from eliminating redundant context. In monolithic exposure, every tool schema remains in context throughout the entire interaction. The hierarchical approach maintains only the minimal necessary information at each stage: category lists and tool lists during discovery, and selected tool schemas during parameter specification.
While monolithic token usage grows linearly with catalog size, hierarchical token usage remains essentially constant regardless of whether your agent is managing 20 tools or 200.
The Intelligence Focusing Effect
It's interesting to think that hierarchical tool discovery helps language models focus their attention. The same model, freed from semantic crowding through progressive disclosure, demonstrates higher quality reasoning about tool selection, parameter construction and task execution.
This suggests that much of what we attribute to model limitations might actually be architectural limitations in how we present information. The improvements indicate that the necessary intelligence was present but was being systematically degraded by poor information architecture.
Information architectures like progressive disclosure date back decades in human-computer interaction research, and this research is a reminder that thoughtful information architecture remains as critical for language models as it has always been for human interfaces.
The principle extends beyond tool use to any complex reasoning task. By carefully managing what information is presented when, we can preserve models' attention budget for the tokens that are actually worth paying attention to.
The results suggest that one of the paths forward for more capable agents and cognitive ability is in designing systems that work with, rather than against, the fundamental characteristics of transformer architectures.
Research Limitations
This research was obviously limited in scale and scope. The experiments were conducted with a small set of models and test cases, and I hope eventually re-run this research with more models across more comprehensive test suites.